OpenShift Cheatsheet
A practical OpenShift knowledge base — cheat sheets, commands, troubleshooting tips, and admin notes for real-world cluster operations. The sidebar mirrors the folder structure of the openshift-cheatsheet repo.
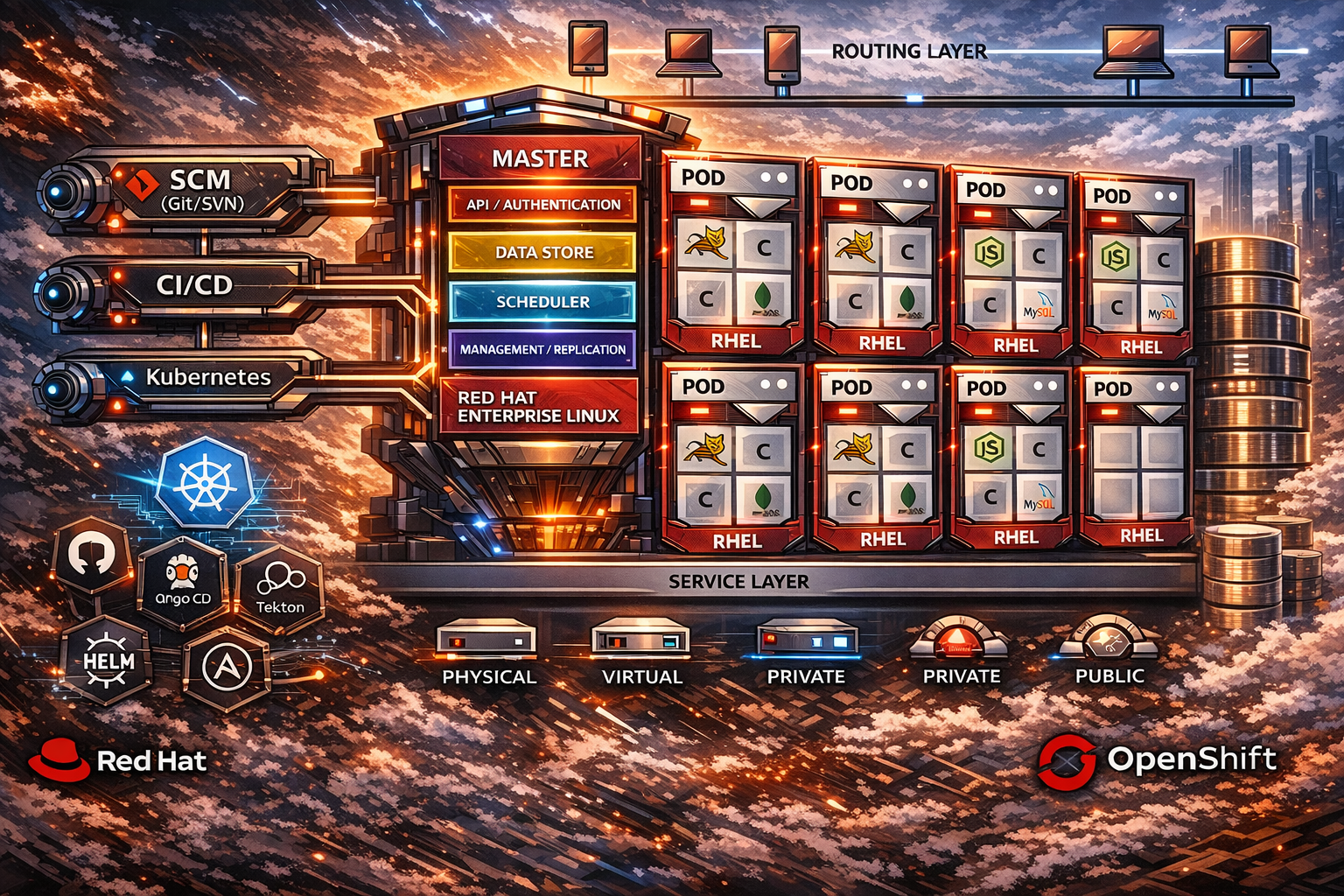
Table of Contents
- Login and Configuration
- Useful Commands
- Deployments
- ConfigMaps
- Managing Routes
- Managing Services
- Resource Usage
- Clean up Resources
- Jobs
- Cluster
- RBAC
- Identity Providers
- Images
- Cluster Version
- Machine Config
- OVN
- Monitoring
- Operator-Lifecycle-Manager (OLM)
- Routers
- Storage
- Pull Secrets
- Registries
- OpenShift Container Platform Troubleshooting
- Troubleshooting
- ETCD
- Security
- Certificates
- API
- Miscellaneous Commands
- ODF
Login and Configuration
oc client download
export OCP_VERSION=latest-4.16curl -k https://mirror.openshift.com/pub/openshift-v4/clients/ocp/$OCP_VERSION/openshift-client-linux.tar.gz -o oc.tar.gzoc Autocompletion
oc completion bash >>/etc/bash_completion.d/oc_completion
echo 'source <(oc completion bash)' >> ~/.bashrcsource ~/.bashrcLogin with a user
oc login https://console-openshift-console.apps-crc.testing:8443 -u developer -p developerLogin as system admin
oc login -u system:adminUser Information
oc whoamioc whoami --show-consoleoc whoami --show-server
oc -info
oc cluster-info dumpView your configuration
oc config viewView your VSphere Credential [https://access.redhat.com/solutions/6677901]
oc get secret vsphere-creds -o yaml -n kube-systemoc get cm cloud-provider-config -o yaml -n openshift-configoc get infrastructures.config.openshift.io -o yamlFix VSphere Credential [https://access.redhat.com/solutions/6677901]
https://access.redhat.com/solutions/6677901oc get secret vsphere-creds -o yaml -n kube-systemoc patch kubecontrollermanager cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=mergeUpdate the current context to have users login to the desired namespace
oc config set-context `oc config current-context` --namespace=<project_name>List OAuth Access Tokens
oc get useroauthaccesstokensUseful Commands
List all Projects
oc get projectsSwitch to a Project
oc project myprojectGet Resources in a Project
List all resources in the current project:
oc get allList pods with custom output:
oc get pods -o wideApply Configuration from a File
oc apply -f config.yamlCreate Objects Using Bash Here Documents
Create a ConfigMap directly using a here document:
oc apply -f - <<EOFapiVersion: v1kind: ConfigMapmetadata: name: example-config namespace: myprojectdata: key: valueEOFExport Resources to a File
oc get deployment my-deployment -o yaml > deployment.yamlDelete a Resource
oc delete pod my-podDebug a Pod
Start a debug session for a pod:
oc debug pod/my-podCheck Cluster Status
oc statusView Cluster Nodes
oc get nodesDescribe a Node
oc describe node <node-name>List nodes CPU/RAM
{ echo -e "NAME\tROLES\tCPU\tMEMORY" paste \ <(oc get nodes --no-headers | awk '{print $1 "\t" $3}') \ <(oc get nodes --no-headers -o custom-columns=CPU:.status.capacity.cpu,MEMORY:.status.capacity.memory)} | column -tView Nodes allocation
for i in $(oc get nodes | awk '{print $1}'); do echo "==== $i ====";oc describe node $i 2> /dev/null | grep -A10 Allocated; echo; done
oc get nodes \ -o custom-columns=NAME:.metadata.name,CPU:.status.capacity.cpu,MEMORY:.status.capacity.memory,EPHEMERAL:.status.capacity.ephemeral-storage,ALLOC_CPU:.status.allocatable.cpu,ALLOC_MEM:.status.allocatable.memory,ALLOC_EPHEMERAL:.status.allocatable.ephemeral-storage
oc get nodes --no-headers | awk '{print $1}' | while read -r n; do echo "===== $n =====" oc describe node "$n" | egrep "^(Name:|Roles:|Capacity:|Allocatable:| cpu:| memory:| ephemeral-storage:|Allocated resources:)" echodoneView Nodes Taints
oc get nodes -o custom-columns=NAME:.metadata.name,TAINTS:.spec.taintsView Nodes Rendered MachineConfig
for n in $(oc get nodes -l node-role.kubernetes.io/master -o name); do echo -n "$n -> " oc get $n -o jsonpath='{.metadata.annotations.machineconfiguration\.openshift\.io/currentConfig}{" | "}{.metadata.annotations.machineconfiguration\.openshift\.io/desiredConfig}{" | "}{.metadata.annotations.machineconfiguration\.openshift\.io/state}{"\n"}'donefstrim Nodes to free space
for i in $(oc get node -l '!node-role.kubernetes.io/master' -o name); do oc debug $i -- chroot /host fstrim -av; doneGet Logs for a Pod
oc logs my-podFollow Logs for a Pod
oc logs -f my-podPort Forward a Pod
oc port-forward my-pod 8080:80Execute a Command in a Running Pod
oc exec my-pod -- ls /tmpScale a Deployment
oc scale deployment my-deployment --replicas=3Create a New Application
oc new-app my-image-streamList resource name by selector
oc get gw -A -o json | jq -r '.items[] | select(.spec.selector.istio == "backend-ingressgateway") | .metadata.name'List nodeSelector per deployment
oc get deployments -A -o json | jq -r '.items[] | "\(.metadata.namespace)/\(.metadata.name): \(.spec.template.spec.nodeSelector)"'Manage Kubeconfig Files
Switch kubeconfig contexts:
oc config use-context <context-name>List all contexts:
oc config get-contextsSet a specific context as default:
oc config set-context --current --namespace=myprojectMerge multiple kubeconfig files:
KUBECONFIG=config1:config2:config3 oc config view --merge --flatten > merged-configCreate a new app from a GitHub Repository
oc new-app https://github.com/sclorg/cakephp-exNew app from a different branch
oc new-app --name=html-dev nginx:1.10~https://github.com/joe-speedboat/openshift.html.devops.git#mybranchCreate objects from a file
oc create -f myobject.yaml -n myprojectDelete objects contained in a file
oc delete -f myobject.yaml -n myprojectCreate or merge objects from a file
oc apply -f myobject.yaml -n myprojectUpdate existing object
oc patch svc mysvc --type merge --patch '{"spec":{"ports":[{"port": 8080, "targetPort": 5000}]}}'Monitor Pod status
watch oc get podsGet a Specific Item (podIP) using a Go template
oc get pod example-pod-2 --template='{{.status.podIP}}'Gather information on a project’s pod deployment with node information
oc get pods -o wideHide inactive Pods
oc get pods --show-all=falseDisplay all resources
oc get all,secret,configmapGet the OpenShift Console Address
oc get -n openshift-console route consoleGet the Pod name from the Selector and rsh into it
POD=$(oc get pods -l app=myapp -o name) oc rsh -n $PODExecute a single command in a running pod
oc exec $POD $COMMANDCreate a pod for the container image “fedora” and execute commands with it
oc run fedora-pod --image=fedora --restart=Never --command -- sleep infinityCopy from local folder byteman-4.0.12 to Pod wildfly-basic-1-mrlt5 under the folder /opt/wildfly
oc cp ./byteman-4.0.12 wildfly-basic-1-mrlt5:/opt/wildflyCreate Infra MachineSets + Move router, registry, monitoring to infra nodes
apiVersion: machine.openshift.io/v1beta1kind: MachineSetmetadata: annotations: machine.openshift.io/memoryMb: "32768" machine.openshift.io/vCPU: "8" labels: hive.openshift.io/machine-pool: worker hive.openshift.io/managed: "true" machine.openshift.io/cluster-api-cluster: ocp01-prod-hkhmm name: ocp01-prod-hkhmm-infra-0 namespace: openshift-machine-apispec: replicas: 3 selector: matchLabels: machine.openshift.io/cluster-api-cluster: ocp01-prod-hkhmm machine.openshift.io/cluster-api-machineset: ocp01-prod-hkhmm-infra-0 template: metadata: labels: machine.openshift.io/cluster-api-cluster: ocp01-prod-hkhmm machine.openshift.io/cluster-api-machine-role: worker machine.openshift.io/cluster-api-machine-type: worker machine.openshift.io/cluster-api-machineset: ocp01-prod-hkhmm-infra-0 spec: lifecycleHooks: {} metadata: labels: node-role.kubernetes.io/infra: "" providerSpec: value: apiVersion: machine.openshift.io/v1beta1 kind: VSphereMachineProviderSpec credentialsSecret: name: vsphere-cloud-credentials diskGiB: 150 memoryMiB: 32768 metadata: creationTimestamp: null network: devices: - networkName: 2245-AGOS-LAN-OCP01-PROD numCPUs: 8 numCoresPerSocket: 1 snapshot: "" template: ocp01-prod-hkhmm-rhcos-generated-region-generated-zone userDataSecret: name: worker-user-data workspace: datacenter: ACME datastore: /ACME/datastore/BT/LUN-BT-OPENSHIFT-250 folder: /ACME/vm/AGOS_OCP_OCP01_PROD resourcePool: /ACME/host/ClusterLNX01/Resources server: agsvcs001.acme.it taints: - effect: NoSchedule key: node-role.kubernetes.io/infra---
oc patch ingresscontroller/default -n openshift-ingress-operator --type=merge -p '{ "spec":{ "nodePlacement":{ "nodeSelector":{ "matchLabels":{ "node-role.kubernetes.io/infra":"" } }, "tolerations":[ { "key":"node-role.kubernetes.io/infra", "operator":"Exists", "effect":"NoSchedule" } ] } }}'
oc patch ingresscontroller/default -n openshift-ingress-operator --type=merge -p '{ "spec":{ "replicas":3 }}'
oc patch configs.imageregistry.operator.openshift.io/cluster --type=merge -p '{ "spec":{ "nodeSelector":{ "node-role.kubernetes.io/infra":"" }, "tolerations":[ { "key":"node-role.kubernetes.io/infra", "operator":"Exists", "effect":"NoSchedule" } ] }}'
apiVersion: v1kind: ConfigMapmetadata: name: cluster-monitoring-config namespace: openshift-monitoringdata: config.yaml: |+ alertmanagerMain: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra operator: Exists effect: NoSchedule
prometheusK8s: retention: 7d nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra operator: Exists effect: NoSchedule volumeClaimTemplate: spec: storageClassName: thin resources: requests: storage: 100Gi
prometheusOperator: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra operator: Exists effect: NoSchedule
metricsServer: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra operator: Exists effect: NoSchedule
k8sPrometheusAdapter: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra operator: Exists effect: NoSchedule
kubeStateMetrics: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra operator: Exists effect: NoSchedule
telemeterClient: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra operator: Exists effect: NoSchedule
openshiftStateMetrics: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra operator: Exists effect: NoSchedule
thanosQuerier: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra operator: Exists effect: NoSchedule
monitoringPlugin: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra operator: Exists effect: NoSchedule
oc apply -f cluster-monitoring-configmap.yamlDeployments
Manual deployment
oc rollout latest ruby-exRollout a Deployment
oc rollout latest deployment/my-deploymentPause a Deployment
oc rollout pause deployment/my-deploymentResume a Deployment
oc rollout resume deployment/my-deploymentScale a Deployment
oc scale deployment/my-deployment --replicas=3Undo a Deployment Rollout
oc rollout undo deployment/my-deploymentCheck Deployment History
oc rollout history deployment/my-deploymentSet Deployment Strategies
spec: strategy: type: Rolling rollingParams: intervalSeconds: 1 updatePeriodSeconds: 1 timeoutSeconds: 600 maxUnavailable: 25% maxSurge: 25%Define resource requests and limits in DeploymentConfig
oc set resources deployment nginx --limits=cpu=200m,memory=512Mi --requests=cpu=100m,memory=256MiDefine livenessProbe and readinessProbe in DeploymentConfig
oc set probe dc/nginx --readiness --get-url=http://:8080/healthz --initial-delay-seconds=10oc set probe dc/nginx --liveness --get-url=http://:8080/healthz --initial-delay-seconds=10Scale the number of Pods to 2
oc scale dc/nginx --replicas=2Define Horizontal Pod Autoscaler (HPA)
oc autoscale dc foo --min=2 --max=4 --cpu-percent=10LIST DEPLOY/REPLICAS x NAMESPACE (DR-check)
kubectl get deploy,pod -A -o json | jq -r ' .items[] | select(.metadata.namespace | test("^(openshift-|kube-|default$|registry$|istio|dyna|sentinel|turbo|zabbix|operator|cluster-management)")==false) | if .kind=="Deployment" then { ns: .metadata.namespace, deploys: 1, desired: (.spec.replicas // 0), available: (.status.availableReplicas // 0), pods: 0, notready: 0 } elif .kind=="Pod" and (.metadata.deletionTimestamp | not) and (.status.phase == "Running" or .status.phase == "Pending") then { ns: .metadata.namespace, deploys: 0, desired: 0, available: 0, pods: 1, notready: ( if ([.status.containerStatuses[]? | select(.ready==false)] | length) > 0 then 1 else 0 end ) } else empty end' | jq -sr ' group_by(.ns)[] | [ .[0].ns, (map(.deploys) | add), (map(.desired) | add), (map(.available) | add), (map(.pods) | add), (map(.notready) | add) ] | @tsv' | (echo -e "NAMESPACE\tN_DEPLOY\tDESIRED_REPLICAS\tAVAILABLE_REPLICAS\tACTIVE_PODS\tPOD_NON_READY"; cat) | column -t -s $'\t'
---alias k8s-ns-report='kubectl get deploy,pod -A -o json | jq -r ".items[]| select(.metadata.namespace | test(\"^(openshift-|kube-|default$|registry$|istio|dyna|sentinel|turbo|zabbix|operator|cluster-management)\")==false)| if .kind==\"Deployment\" then { ns: .metadata.namespace, deploys: 1, desired: (.spec.replicas // 0), available: (.status.availableReplicas // 0), pods: 0, notready: 0 } elif .kind==\"Pod\" and (.metadata.deletionTimestamp | not) and (.status.phase == \"Running\" or .status.phase == \"Pending\") then { ns: .metadata.namespace, deploys: 0, desired: 0, available: 0, pods: 1, notready: ( if ([.status.containerStatuses[]? | select(.ready==false)] | length) > 0 then 1 else 0 end ) } else empty end" | jq -sr "group_by(.ns)[]| [ .[0].ns, (map(.deploys) | add), (map(.desired) | add), (map(.available) | add), (map(.pods) | add), (map(.notready) | add) ]| @tsv" | (echo -e "NAMESPACE\tN_DEPLOY\tDESIRED_REPLICAS\tAVAILABLE_REPLICAS\tACTIVE_PODS\tPOD_NON_READY"; cat) | column -t -s $'\''\t'\'''ConfigMaps
View ConfigMap Data
oc get configmap my-config -o yamlUpdate a ConfigMap
oc create configmap my-config --from-literal=key=value --dry-run=client -o yaml | oc apply -f -Managing Routes
Create a route
oc expose service ruby-exCreate Route and expose it through a custom Hostname
oc expose service ruby-ex --hostname=<custom-hostname>Read the Route Host attribute
oc get route my-route -o jsonpath --template="{.spec.host}"Forward traffic from pod “myphp” from 8080 to local 8080
oc port-forward pod/myphp 8080:8080Managing Services
Make a service idle. When the service is next accessed it will automatically boot up the pods again
oc idle ruby-exRead a Service IP
oc get services rook-ceph-mon-a --template='{{.spec.clusterIP}}'Resource Usage
List the memory and CPU usage of all pods in the cluster
oc adm top pods -A --sumList the resource usage of the containers in the pod “mypod” in the “example” namespace
oc adm top pods mypod -n example --containersResource consumption for the node
oc adm top nodeList all resources, their status, and their types in the “example” namespace
oc get all -n example --show-kindDisplays the resource consumption for each container running on the node (requires “cri-tools”)
crictl statsClean up Non Running pods
oc get pods -A -o wide | grep -v 'Runn\|Comp'oc get pods -A | grep -v 'Runn\|Comp' | grep openshift | awk 'system("oc delete pods "$2" -n "$1" --force --grace-period=0")'Delete Completed Pods
oc delete pod --field-selector=status.phase==Succeeded --all-namespacesoc get pods --all-namespaces | awk '{if ($4 == "Completed") system ("oc delete pod " $2 " -n " $1 )}'
read -p "Namespace: " ns; read -p "Stato (e.g. Error, Completed): " status; oc get pods -n "$ns" --no-headers | awk -v s="$status" '$3 == s { system("oc delete pod " $1 " -n " "'$ns'") }'
oc delete pod --field-selector=status.phase==Failed --all-namespacesoc delete pod --field-selector=status.phase==Pending --all-namespacesoc delete pod --field-selector=status.phase==Evicted --all-namespacesoc get pods --all-namespaces | awk '{if ($4 != "Running") system ("oc delete pod " $2 " -n " $1 )}'Change the image garbage collection (GC) thresholds
Modify kubelet GC settings:
oc label machineconfigpool worker custom-kubelet=enabledcat <<EOF | oc apply -f -apiVersion: machineconfiguration.openshift.io/v1kind: KubeletConfigmetadata: name: custom-configspec: machineConfigPoolSelector: matchLabels: custom-kubelet: enabled kubeletConfig: ImageGCHighThresholdPercent: 70 ImageGCLowThresholdPercent: 60EOFFull cleanup with Podman
Run a full system prune:
sudo podman system prune -a -fDelete all resources
oc delete all --allDelete resources for one specific app
oc delete services -l app=ruby-exoc delete all -l app=ruby-exClean up old docker images on nodes
Keeping up to three tag revisions and resources younger than sixty minutes
oc adm prune images --keep-tag-revisions=3 --keep-younger-than=60mPruning every image that exceeds defined limits
oc adm prune images --prune-over-size-limitJobs
Create a simple Job
kubectl create job hello --image=alpine -- echo "Hello World"Create a CronJob that prints “Hello World” every minute
kubectl create cronjob hello --image=alpine --schedule="*/1 * * * *" -- echo "Hello World"Cluster
Set control-plane nodes as NoSchedulable
oc patch schedulers.config.openshift.io/cluster --type merge --patch '{"spec":{"mastersSchedulable": false}}'This removes the worker label from the masters. OpenShift components will move to worker nodes when rescheduled. Delete the pods to trigger reconciliation.
Set a Default Node Selector
oc patch namespace default -p '{"metadata": {"annotations": {"openshift.io/node-selector": "node-role.kubernetes.io/worker"}}}'Disable Project-wide Node Selector
oc annotate namespace default openshift.io/node-selector-Routers
Rollout the latest deployment
oc rollout -n openshift-ingress restart deployment/router-defaultDelete router pods to force reconciliation
oc delete pod -n openshift-ingress -l ingresscontroller.operator.openshift.io/deployment-ingresscontroller=defaultRBAC
List role per groups
oc get rolebindings,clusterrolebindings --all-namespaces -o json | jq -r '.items[] |select(.subjects[]? | select(.kind == "Group")) as $binding |$binding.subjects[] |select(.kind == "Group") |"NAMESPACE: \($binding.metadata.namespace // "Cluster-wide") KIND: \($binding.kind) NAME: \($binding.metadata.name) ROLE: \($binding.roleRef.name) GROUP: \(.name)"'List all users/groups with cluster-admin rights
oc get clusterrolebindings -o json | jq '.items[] | select(.roleRef.name=="cluster-admin")' | jq '.subjects[0].name'List all cluster-role / role
oc get clusterroles -o json | jq '.items[].metadata.name'oc get roles -o json | jq '.items[].metadata.name'Add a role to a user
oc adm policy add-role-to-user admin oia -n pythonAdd a cluster role to a user
oc adm policy add-cluster-role-to-user cluster-reader system:serviceaccount:monitoring:defaultAdd a security context constraint (SCC) to a user
oc adm policy add-scc-to-user anyuid -z defaultVerify user permission
oc auth can-i command --as user_to_impersonate \ --as-group group_to_impersonate
oc auth can-i get pods -A \ --as system:serviceaccount:auth-tls:health-robot
oc auth can-i create project -A \ --as system:serviceaccount:auth-tls:health-robot
oc auth can-i get users -A \ --as admin-backdoor --as-group backdoor-administratorsVerify user permission
oc get nodes --as adminShow SCC and add policy
oc get pods -A -o custom-columns="NAME:.metadata.name,SCC:.metadata.annotations.openshift\.io/scc"oc get pods -o custom-columns="NAME:.metadata.name,SECURITY_CONTEXT:.spec.securityContext"
oc get deployment <DEPLOY> -n <NAMESPACE> -o yaml | oc adm policy scc-subject-review -f -oc get pod <POD> -o yaml | oc adm policy scc-subject-review -f -
oc adm policy add-scc-to-user hostmount-anyuid -z default
oc get scc -o custom-columns=Name:.metadata.name,Users:.users,Priority:.priorityoc get scc restricted-v2 -o custom-columns=SECCOMP_PROFILE:.seccompProfilesIdentity Providers
Add an HTPasswd Identity Provider
Create a secret with the htpasswd file:
oc create secret generic htpass-secret --from-file=htpasswd=/path/to/htpasswd -n openshift-configPatch the OAuth resource to add the htpasswd provider:
apiVersion: config.openshift.io/v1kind: OAuthmetadata: name: clusterspec: identityProviders: - name: my_htpasswd_provider mappingMethod: claim type: HTPasswd htpasswd: fileData: name: htpass-secretApply the configuration:
oc apply -f oauth.yamlAdd a GitHub Identity Provider
Create a GitHub OAuth client:
oc create secret generic github-secret --from-literal=clientSecret=<your-client-secret> -n openshift-configPatch the OAuth resource to add the GitHub provider:
apiVersion: config.openshift.io/v1kind: OAuthmetadata: name: clusterspec: identityProviders: - name: github mappingMethod: claim type: GitHub github: clientID: <your-client-id> clientSecret: name: github-secret organizations: - my-orgApply the configuration:
oc apply -f oauth.yamlOpenShift Authentication / LDAP
1. Stato rapido
oc get co authentication console ingressoc -n openshift-authentication get pods -o wideoc get oauth cluster -o yaml2. Log OAuth con errori LDAP/TLS/timeout
for p in $(oc -n openshift-authentication get pod -l app=oauth-openshift -o name); do echo "### $p" oc -n openshift-authentication logs "$p" --since=30m | \ egrep -i 'AuthenticationError|ldap|x509|tls|invalid credentials|claimed by identity|not found|no such object|timeout'done3. Test LDAPS da tutti i pod OAuth — versione breve
for p in $(oc -n openshift-authentication get pod -l app=oauth-openshift -o name); do echo -n "$p -> " oc -n openshift-authentication exec "$p" -- bash -lc ' timeout 5 bash -c "cat < /dev/null > /dev/tcp/10.213.48.178/636" >/dev/null 2>&1 \ && echo OK || echo FAIL 'done4. Test LDAPS da tutti i pod OAuth — versione estesa
for p in $(oc -n openshift-authentication get pod -l app=oauth-openshift -o name); do echo "### $p" oc -n openshift-authentication exec "$p" -- bash -lc ' echo "HOST=$(hostname)" getent hosts msad1.cariprpc.it || true cat /etc/resolv.conf echo -n "TCP636: " timeout 5 bash -c "cat < /dev/null > /dev/tcp/10.213.48.178/636" && echo OK || echo FAIL 'done5. Test LDAPS via DNS invece che IP
for p in $(oc -n openshift-authentication get pod -l app=oauth-openshift -o name); do echo -n "$p -> " oc -n openshift-authentication exec "$p" -- bash -lc ' timeout 5 bash -c "cat < /dev/null > /dev/tcp/msad1.cariprpc.it/636" >/dev/null 2>&1 \ && echo OK || echo FAIL 'done6. Verifica certificato della route OAuth
HOST=$(oc -n openshift-authentication get route oauth-openshift -o jsonpath='{.spec.host}')echo "$HOST"
openssl s_client -connect ${HOST}:443 -servername ${HOST} </dev/null 2>/dev/null | \openssl x509 -noout -subject -issuer -dates7. Verifica reachability LDAP dai nodi master (host network)
for n in ocpapp-dr-g5t4w-master-0 ocpapp-dr-g5t4w-master-1 ocpapp-dr-g5t4w-master-2; do echo "### $n" oc debug node/$n -- chroot /host bash -lc ' echo -n "NODE=$(hostname) TCP636: " timeout 5 bash -c "cat < /dev/null > /dev/tcp/10.213.48.178/636" && echo OK || echo FAIL echo -n "ROUTE: " ip route get 10.213.48.178 2>/dev/null || true 'done8. NetworkPolicy nel namespace openshift-authentication
oc get netpol -n openshift-authentication -o yaml9. Restart mirato di un solo pod OAuth
oc delete pod -n openshift-authentication <oauth-openshift-pod>oc -n openshift-authentication get pods -w
---
## **Images**
### List All Images in the Cluster```bashoc get imagesImport an Image from an External Registry
oc import-image myimage:latest --from=docker.io/library/myimage:latest --confirmTag an Image for Internal Use
oc tag myimage:latest myproject/myimage:stablePrune Unused Images
oc adm prune images --confirmBuild an Image from Source Code
oc new-build https://github.com/openshift/ruby-hello-world.git --name=ruby-appStart a Build
oc start-build ruby-appMonitor Build Logs
oc logs -f bc/ruby-appDeploy an Image
oc new-app myimage:stable -n myprojectImage Registry
Rollout the latest deployment
oc rollout -n openshift-image-registry restart deploy/image-registryDelete image registry pods
oc delete pod -n openshift-image-registry -l docker-registry=defaultMonitoring Stack
Rollout the latest deployments and statefulsets
oc rollout -n openshift-monitoring restart statefulset/alertmanager-mainoc rollout -n openshift-monitoring restart statefulset/prometheus-k8soc rollout -n openshift-monitoring restart deployment/grafanaoc rollout -n openshift-monitoring restart deployment/kube-state-metricsoc rollout -n openshift-monitoring restart deployment/openshift-state-metricsoc rollout -n openshift-monitoring restart deployment/prometheus-adapteroc rollout -n openshift-monitoring restart deployment/telemeter-clientoc rollout -n openshift-monitoring restart deployment/thanos-querierDelete monitoring stack pods to force reconciliation
oc delete pod -n openshift-monitoring -l app=alertmanageroc delete pod -n openshift-monitoring -l app=prometheusoc delete pod -n openshift-monitoring -l app=grafanaoc delete pod -n openshift-monitoring -l app.kubernetes.io/name=kube-state-metricsoc delete pod -n openshift-monitoring -l k8s-app=openshift-state-metricsoc delete pod -n openshift-monitoring -l name=prometheus-adapteroc delete pod -n openshift-monitoring -l k8s-app=telemeter-clientoc delete pod -n openshift-monitoring -l app.kubernetes.io/component=query-layerList All Container Images
List all container images running in a cluster
oc get pods -A -o go-template --template='{{range .items}}{{range .spec.containers}}{{printf "%s\\n" .image -}} {{end}}{{end}}' | sort -u | uniqList all container images stored in a cluster
for node in $(oc get nodes -o name); do oc debug ${node} -- chroot /host sh -c 'crictl images -o json' 2>/dev/null | jq -r .images[].repoTags[];done | sort -uCluster Upgrade
oc get clusterversionoc adm upgradeoc patch clusterversion version --type merge -p '{"spec":{"channel":"stable-4.14"}}'oc adm upgrade --to=4.14.10watch oc get clusterversionoc get coSwitch Cluster Version Channel
oc patch \ --patch='{"spec": {"channel": "prerelease-4.1"}}' \ --type=merge \ clusterversion/versionUnmanage Operators
Retrieve current overrides
oc get -o json clusterversion version | jq .spec.overridesAdd a ComponentOverride to set the network operator unmanaged
-
Extract the operator definition:
Terminal window head -n5 /tmp/mystuff/0000_07_cluster-network-operator_03_daemonset.yamlExample:
apiVersion: apps/v1kind: Deploymentmetadata:name: network-operatornamespace: openshift-network-operator -
Create the patch YAML file: If no overrides exist:
- op: addpath: /spec/overridesvalue:- kind: Deploymentgroup: appsname: network-operatornamespace: openshift-network-operatorunmanaged: trueIf overrides already exist:
- op: addpath: /spec/overrides/-value:- kind: Deploymentgroup: appsname: network-operatornamespace: openshift-network-operatorunmanaged: true -
Apply the patch:
Terminal window oc patch clusterversion version --type json -p "$(cat version-patch.yaml)"
Verify
oc get -o json clusterversion version | jq .spec.overridesDisabling the Cluster Version Operator
oc scale --replicas 0 -n openshift-cluster-version deployments/cluster-version-operatorMachine Config
List all MachineConfig objects
oc get machineconfigsView details of a specific MachineConfig
oc describe machineconfig <machineconfig-name>Create a custom MachineConfig
Example YAML:
apiVersion: machineconfiguration.openshift.io/v1kind: MachineConfigmetadata: name: custom-config labels: machineconfiguration.openshift.io/role: workerspec: config: ignition: version: 3.2.0 storage: files: - path: /etc/mycustomconfig contents: source: data:,custom%20content%20hereApply the configuration:
oc apply -f custom-config.yamlUpdate Kubelet Configuration
Create a KubeletConfig:
apiVersion: machineconfiguration.openshift.io/v1kind: KubeletConfigmetadata: name: custom-kubeletspec: machineConfigPoolSelector: matchLabels: custom-kubelet: enabled kubeletConfig: cpuManagerPolicy: "static" cpuManagerReconcilePeriod: "5s"Apply the configuration:
oc apply -f kubelet-config.yamlUpdate MCP maxUnavailable
oc patch --type merge machineconfigpool/<machineconfigpool> -p '{"spec":{"maxUnavailable":<value>}}'Pause/Unpause MCP
oc patch mcp/<mcp_name> --patch '{"spec":{"paused":true}}' --type=mergeoc patch mcp/<mcp_name> --patch '{"spec":{"paused":false}}' --type=mergeScale Up Control Plane Machineset
oc patch controlplanemachineset.machine.openshift.io cluster -n openshift-machine-api --type=merge -p '{"spec":{"template":{"machines_v1beta1_machine_openshift_io":{"spec":{"providerSpec":{"value":{"numCPUs":8,"memoryMiB":32768}}}}}}}'Monitoring
List Monitoring Stack Components
oc get pods -n openshift-monitoringRestart a Monitoring Component
oc rollout restart deployment/grafana -n openshift-monitoringSilence Alerts
Create a silence using the Alertmanager UI or CLI. Example CLI:
amtool silence add alertname="TargetDown" instance="example-instance"Query Prometheus
Access the Prometheus UI or use oc to query:
oc exec -n openshift-monitoring prometheus-k8s-0 -c prometheus -- curl 'http://localhost:9090/api/v1/query?query=up'Enable User Workload Monitoring
Patch the config to enable it:
oc patch configmap cluster-monitoring-config -n openshift-monitoring --patch='{"data":{"config.yaml":"enableUserWorkload: true"}}'Monitor Custom Metrics
Deploy a custom application exposing metrics and configure Prometheus to scrape them by creating a ServiceMonitor:
apiVersion: monitoring.coreos.com/v1kind: ServiceMonitormetadata: name: custom-app-monitor labels: team: custom-appspec: selector: matchLabels: app: custom-app endpoints: - port: metricsApply the configuration:
oc apply -f custom-app-monitor.yamlOVN
OpenShift OVN-Kubernetes
1. Stato rapido dei pod OVN sui master
oc get pods -n openshift-ovn-kubernetes -o wide | \ egrep 'ovnkube-node|ovnkube-control-plane|master-0|master-1|master-2'2. Stato dei container degli ovnkube-node
for p in $(oc get pods -n openshift-ovn-kubernetes -l app=ovnkube-node -o jsonpath='{range.items[*]}{.metadata.name}{"\n"}{end}'); do echo "=== $p ===" oc get pod -n openshift-ovn-kubernetes "$p" -o json | \ jq -r '.spec.nodeName, (.status.containerStatuses[] | "\(.name)=\(.ready)")'done3. Eventi recenti di OVN
oc get events -n openshift-ovn-kubernetes --sort-by=.lastTimestamp | tail -1004. Log utili degli ovnkube-node sui 3 master
for p in ovnkube-node-kd568 ovnkube-node-tcr28 ovnkube-node-ms268; do echo "### $p : ovn-controller" oc logs -n openshift-ovn-kubernetes $p -c ovn-controller --since=2h | \ egrep -i 'error|warn|timeout|conntrack|openflow|geneve|health|route|gateway|mtu'
echo "### $p : ovnkube-controller" oc logs -n openshift-ovn-kubernetes $p -c ovnkube-controller --since=2h | \ egrep -i 'error|warn|timeout|egress|route|gateway|management port'done5. Log del control plane OVN
for p in $(oc get pods -n openshift-ovn-kubernetes -l app=ovnkube-control-plane -o name); do echo "### $p" oc logs -n openshift-ovn-kubernetes "$p" -c ovnkube-cluster-manager --since=2h | \ egrep -i 'error|warn|timeout|master|node|egress|route|gateway'done6. PodNetworkConnectivityCheck verso i master
for x in \ network-check-source-ocpapp-dr-g5t4w-worker-0-t56f7-to-network-check-target-ocpapp-dr-g5t4w-master-0 \ network-check-source-ocpapp-dr-g5t4w-worker-0-t56f7-to-network-check-target-ocpapp-dr-g5t4w-master-1 \ network-check-source-ocpapp-dr-g5t4w-worker-0-t56f7-to-network-check-target-ocpapp-dr-g5t4w-master-2 do echo "### $x" oc get podnetworkconnectivitycheck -n openshift-network-diagnostics "$x" -o yaml | \ sed -n '/status:/,$p'done7. Test host network dei master verso LDAP
for n in ocpapp-dr-g5t4w-master-0 ocpapp-dr-g5t4w-master-1 ocpapp-dr-g5t4w-master-2; do echo "### $n" oc debug node/$n -- chroot /host bash -lc ' echo -n "NODE=$(hostname) TCP636: " timeout 5 bash -c "cat < /dev/null > /dev/tcp/10.213.48.178/636" && echo OK || echo FAIL echo -n "ROUTE: " ip route get 10.213.48.178 2>/dev/null || true 'done8. Test pod network dai pod OAuth verso LDAP
for p in $(oc -n openshift-authentication get pod -l app=oauth-openshift -o name); do echo -n "$p -> " oc -n openshift-authentication exec "$p" -- bash -lc ' timeout 5 bash -c "cat < /dev/null > /dev/tcp/10.213.48.178/636" >/dev/null 2>&1 \ && echo OK || echo FAIL 'done9. Restart mirato degli ovnkube-node sui master problematici
Master-0
oc delete pod -n openshift-ovn-kubernetes ovnkube-node-kd568oc get pod -n openshift-ovn-kubernetes -w | grep ovnkube-node-kd568Master-1
oc delete pod -n openshift-ovn-kubernetes ovnkube-node-tcr28oc get pod -n openshift-ovn-kubernetes -w | grep ovnkube-node-tcr2810. Ritest dopo restart OVN
for p in $(oc -n openshift-authentication get pod -l app=oauth-openshift -o name); do echo -n "$p -> " oc -n openshift-authentication exec "$p" -- bash -lc ' timeout 5 bash -c "cat < /dev/null > /dev/tcp/10.213.48.178/636" >/dev/null 2>&1 \ && echo OK || echo FAIL 'doneOperator-Lifecycle-Manager (OLM)
List Installed Operators
oc get csv -n openshift-operatorsoc get csv -A --no-headers -o custom-columns=NAME:.metadata.name,DISPLAY:.spec.displayName,VERSION:.spec.version | sort | uniqInstall an Operator
Create a subscription for the operator:
apiVersion: operators.coreos.com/v1alpha1kind: Subscriptionmetadata: name: my-operator namespace: openshift-operatorsspec: channel: stable name: my-operator source: operatorhubio-catalog sourceNamespace: openshift-marketplaceApply the subscription:
oc apply -f subscription.yamlCheck the Status of an Operator
oc get csv -n openshift-operatorsUninstall an Operator
Delete the subscription and CSV:
oc delete subscription my-operator -n openshift-operatorsoc delete csv my-operator.v1.0.0 -n openshift-operatorsApprove a Manual InstallPlan
oc patch installplan install-xxxxx -n openshift-operators --type merge --patch '{"spec": {"approved": true}}'View Operator Logs
Find the operator’s pod and view logs:
oc get pods -n openshift-operatorsoc logs my-operator-pod -n openshift-operatorsCreate a Custom Resource for an Operator
Example YAML:
apiVersion: app.example.com/v1kind: ExampleAppmetadata: name: example-app namespace: myprojectspec: size: 3Apply the custom resource:
oc apply -f example-app.yamlCheck Operator Conditions
oc get csv my-operator.v1.0.0 -n openshift-operators -o jsonpath='{.status.conditions}'List Available Operators in the Marketplace
oc get packagemanifests -n openshift-marketplaceDescribe a Specific Operator
oc describe packagemanifest my-operator -n openshift-marketplaceUpdate an Operator Subscription
oc patch subscription my-operator -n openshift-operators --type merge --patch '{"spec": {"channel": "stable"}}'Routers
Restart a Router
Restart the default router deployment:
oc rollout restart deployment/router-default -n openshift-ingressList Router Pods
oc get pods -n openshift-ingress -l ingresscontroller.operator.openshift.io/deployment-ingresscontroller=defaultDelete Router Pods to Trigger Reconciliation
oc delete pod -n openshift-ingress -l ingresscontroller.operator.openshift.io/deployment-ingresscontroller=defaultCheck Router Logs
oc logs -n openshift-ingress pod/router-default-xxxxxExpose a Route
Expose a service using a route:
oc expose service my-service --hostname=my.custom.domainList Routes
oc get routes -AStorage
List Persistent Volume Claims (PVCs)
oc get pvc -ADescribe a PVC
oc describe pvc my-pvcCreate a PVC
Example YAML for a PVC:
apiVersion: v1kind: PersistentVolumeClaimmetadata: name: my-pvcspec: accessModes: - ReadWriteOnce resources: requests: storage: 10GiApply the PVC:
oc apply -f pvc.yamlList Storage Classes
oc get storageclassSet Default Storage Class
oc patch storageclass <storage-class-name> -p '{"metadata": {"annotations": {"storageclass.kubernetes.io/is-default-class": "true"}}}'Delete a PVC
oc delete pvc my-pvcCreate a Persistent Volume (PV)
Example YAML for a PV:
apiVersion: v1kind: PersistentVolumemetadata: name: my-pvspec: capacity: storage: 10Gi accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Retain hostPath: path: /mnt/dataApply the PV:
oc apply -f pv.yamlExpand a PVC
Ensure the underlying storage class supports expansion. Then patch the PVC:
oc patch pvc my-pvc -p '{"spec": {"resources": {"requests": {"storage": "20Gi"}}}}'Pull Secrets
Create a Pull Secret
Create a pull secret to authenticate with an external container registry:
oc create secret docker-registry my-pull-secret \ --docker-server=<registry-server> \ --docker-username=<username> \ --docker-password=<password> \ --docker-email=<email>Link a Pull Secret to a ServiceAccount
oc secrets link default my-pull-secret --for=pullView Linked Secrets for a ServiceAccount
oc get serviceaccount default -o yamlUpdate the Global Pull Secret
- Edit the pull secret:
Terminal window oc edit secret pull-secret -n openshift-config - Add the credentials for the desired registry in the
authssection.
Add Credentials to a Namespaced Secret
Create a new secret with updated credentials:
oc create secret docker-registry my-namespace-pull-secret \ --docker-server=<registry-server> \ --docker-username=<username> \ --docker-password=<password> \ --docker-email=<email> -n mynamespaceLink the new secret to a service account:
oc secrets link my-serviceaccount my-namespace-pull-secret --for=pull -n mynamespaceView secret in STDOUT:
oc extract secret my-namespace-pull-secret -n mynamespace --to=-Registries
List Images in the Internal Registry
oc get is -AExpose the Internal Registry Externally
oc patch configs.imageregistry.operator.openshift.io/cluster \ --type merge \ --patch '{"spec":{"defaultRoute":true}}'Retrieve the route:
oc get route default-route -n openshift-image-registryMirror an External Image to the Internal Registry
oc image mirror docker.io/library/nginx:latest \ image-registry.openshift-image-registry.svc:5000/myproject/nginx:latestSet Registry Resource Limits
oc patch configs.imageregistry.operator.openshift.io/cluster \ --type merge \ --patch '{"spec":{"resources":{"requests":{"memory":"1Gi"},"limits":{"memory":"2Gi"}}}}'Prune Old Images
oc adm prune images --confirmForce Garbage Collection on the Internal Registry
oc patch configs.imageregistry.operator.openshift.io/cluster \ --type merge \ --patch '{"spec":{"managementState":"Managed"}}'Run garbage collection:
oc exec -n openshift-image-registry -it $(oc get pods -n openshift-image-registry -l docker-registry=default -o jsonpath='{.items[0].metadata.name}') -- registry garbage-collect /config.ymlOpenShift Container Platform Troubleshooting
Inspect all resources in a namespace
oc adm inspect ns/mynamespaceRun cluster diagnostics
oc adm diagnosticsCollect must-gather
oc adm must-gatherCheck status of the current project
oc statusGet events for a project sorted by timestamp
oc get events --sort-by=.metadata.creationTimestampoc get events --sort-by='.lastTimestamp'Get events of type Warning
oc get ev --field-selector type=Warning -o jsonpath='{.items[].message}{"\n"}'Logs management
Get the logs of a specific pod
oc logs myrunning-pod-2-fdthnFollow the logs of a specific pod
oc logs -f myrunning-pod-2-fdthnTail the logs of a specific pod
oc logs myrunning-pod-2-fdthn --tail=50Check the integrated Docker registry logs
oc logs docker-registry-n-{xxxxx} -n default | lessCreate a temporary namespace to debug the node
oc debug node/master01Troubleshooting
Check Cluster Status
oc statusView Cluster Events
oc get events -A --sort-by=.metadata.creationTimestampCheck Pod Logs
oc logs pod-nameFollow logs for a pod:
oc logs -f pod-nameDebug a Pod
Start a debug session:
oc debug pod/pod-nameInspect a Node
oc debug node/node-nameRestart a Deployment
oc rollout restart deployment/deployment-nameCheck Network Connectivity from a Pod
Use a debug pod to check connectivity:
oc run debug-pod --image=registry.access.redhat.com/ubi8/ubi --restart=Never --command -- sleep infinityoc exec -it debug-pod -- curl -v http://service-name:portDiagnose DNS Issues
Check if DNS resolution works:
oc exec -it pod-name -- nslookup service-nameView Resource Usage
View node resource usage:
oc adm top nodesView pod resource usage:
oc adm top pods -ADescribe Resources
Describe a pod:
oc describe pod pod-nameDescribe a node:
oc describe node node-nameCollect Cluster Diagnostics
oc adm diagnosticsUse Must-Gather
Collect diagnostics using must-gather:
oc adm must-gatherCheck Image Registry Logs
oc logs -n openshift-image-registry deployment/image-registryAnalyze CrashLoopBackOff
Check the previous logs for a pod:
oc logs --previous pod-nameDebug with a Temporary Namespace
Create a temporary debug namespace:
oc new-project debug-namespaceDelete it when done:
oc delete project debug-namespaceReset a Node
Drain and reboot a node:
oc adm drain node-name --ignore-daemonsets --forcerebootStato Kubelet sui nodi
oc get nodes -o jsonpath='{range .items[*]}{.metadata.name}{"\t"}{.status.conditions[?(@.type=="Ready")].status}{"\n"}{end}'Recupero Proxy Cluster
oc get proxy/cluster -o json | jq -r '"export HTTP_PROXY=\(.spec.httpProxy)export HTTPS_PROXY=\(.spec.httpsProxy)export NO_PROXY=\"\(.spec.noProxy)\"export http_proxy=\(.spec.httpProxy)export https_proxy=\(.spec.httpsProxy)export no_proxy=\"\(.spec.noProxy)\""'Disable disableCopiedCSVs parameter to true for the OLMConfig
https://docs.redhat.com/en/documentation/openshift_container_platform/4.16/html/operators/administrator-tasks#olm-disabling-copied-csvs_olm-config
oc apply -f - <<EOFapiVersion: operators.coreos.com/v1kind: OLMConfigmetadata: name: clusterspec: features: disableCopiedCSVs: trueEOFETCD
Check the etcd status:
export ETCD_POD_NAME=$(oc get pods -n openshift-etcd -l app=etcd -o jsonpath='{.items[0].metadata.name}')export ETCD_POD_NAME=$(oc get pods -n openshift-etcd -l app=etcd --field-selector="status.phase==Running" -o jsonpath="{.items[0].metadata.name}")
oc exec -n openshift-etcd -c etcd ${ETCD_POD_NAME} -- etcdctl member list -w tableoc exec -n openshift-etcd -c etcd ${ETCD_POD_NAME} -- etcdctl endpoint health --cluster -w tableoc exec -n openshift-etcd -c etcd ${ETCD_POD_NAME} -- etcdctl endpoint status --cluster -w tableoc exec -n openshift-etcd -c etcd ${ETCD_POD_NAME} -- etcdctl endpoint status --cluster -w json | jq '.[] | ((.Status.dbSize - .Status.dbSizeInUse)/.Status.dbSize)*100'
oc exec -n openshift-etcd -c etcd $ETCD_POD_NAME -- etcdctl alarm listoc exec -n openshift-etcd -c etcd $ETCD_POD_NAME -- etcdctl defrag
oc exec -n openshift-etcd -c etcdctl ${ETCD_POD_NAME} -- sh -c "etcdctl get / --prefix --keys-only | grep -oE '^/[a-z|.]+/[a-z|.|8]*' | sort | uniq -c | sort -rn" | while read KEY; do printf "$KEY\t" && oc exec -n openshift-etcd ${ETCD_POD_NAME} -c etcdctl -- etcdctl get ${KEY##* } --prefix --write-out=json | jq '[.kvs[].value | length] | add ' | numfmt --to=iec ; done | sort -k3 -hr | column -t
for i in `oc get pods -n openshift-etcd | egrep -v "NAME|guard|Succeeded" | awk '{ print $1 }'`; do echo "-- $i"; oc logs $i -c etcd -n openshift-etcd 2>&1 | awk -v min=999 'function norm(p){split($0,a,",");gsub("[tok:\"]","",a[p]);if (a[p] ~ ".*[0-9]s")a[p]*=1000; return a[p]*=1} {if (NR==1) start=$1} /took too long/ {b=norm(5); if (tmin==0) tmin=b; if (b<tmin) tmin=b; if (b>tmax) tmax=b; tavg+=b; t++} /context deadline exceeded/ {d++} /finished scheduled compaction/ {b=norm(6); if (b<min) min=b; if (b>max) max=b; avg+=b; c++} ENDFILE{end=$1} END{if (t==0) t--; printf " Log range:\t\t%s - %s\n took too long:\ttotal %d - min %d - max %d - avg %d\n deadline exceeded:\t%d\n compaction times:\ttotal %d - min %d - max %d - avg %d\n",start,end,t,tmin,tmax,tavg/t,d,c,min,max,avg/c}'; done
oc logs -n openshift-etcd -c etcd $ETCD_POD_NAME --tail=500 | egrep -i 'fsync|slow|leader|timeout|alarm'Diagnostic Steps:
oc get pod -n openshift-etcdoc logs etcd-XYZ-master-0 -c etcd -n openshift-etcdoc rsh -n openshift-etcd <etcd pod>(From inside container run below commands)etcdctl member list -w tableetcdctl endpoint health --clusteretcdctl endpoint status -w table
in case oc command doesn't work, connect with ssh to node and run
crictl logs $(crictl ps -aql --label "io.kubernetes.container.name=etcd-member")crictl logs --since 48h $(crictl ps -aql --label "io.kubernetes.container.name=etcd-member")Collect metrics:
mkdir etcd-metricsfor etcd_pod in `oc get pods -l k8s-app=etcd -n openshift-etcd -o jsonpath='{.items[*].metadata.name}'`; do oc exec -it $etcd_pod -n "openshift-etcd" -c "etcdctl" -- sh -c 'curl --cert $ETCDCTL_CERT --key $ETCDCTL_KEY --cacert $ETCDCTL_CACERT https://localhost:2379/metrics' &> etcd-metrics/${etcd_pod}_metrics.txt;doneCheck the etcd objects:
export ETCD_POD_NAME=$(oc get pods -n openshift-etcd -l app=etcd --field-selector="status.phase==Running" -o jsonpath="{.items[0].metadata.name}")oc exec -n openshift-etcd -c etcdctl ${ETCD_POD_NAME} -- sh -c "etcdctl get / --prefix --keys-only | grep -oE '^/[a-z|.]+/[a-z|.|8]*' | sort | uniq -c | sort -rn" | while read KEY; do printf "$KEY\t" && oc exec -n openshift-etcd ${ETCD_POD_NAME} -c etcdctl -- etcdctl get ${KEY##* } --prefix --write-out=json | jq '[.kvs[].value | length] | add ' | numfmt --to=iec ; done | sort -k3 -hr | column -tCheck the number of etcd objects:
oc project openshift-etcdoc get pooc rsh etcd-pod-namesh-5.1# etcdctl get / --prefix --keys-only | sed '/^$/d' | cut -d/ -f3 | sort | uniq -c | sort -rnBackup ETCD shell:
### 0 0 * * * /usr/local/bin/etcd_backup.sh GCP-PRD 172.26.3.13 >> /home/ocp/backup-etcd/etcd_backup.log 2>&1
cat <<EOF > backup_script.sh#!/bin/bash
# Uso: ./backup_script.sh <Nome Cluster> <IP Master>
if [ "\$#" -ne 2 ]; then echo "Uso: \$0 <Nome Cluster> <IP Master>" exit 1fi
CLUSTER_NAME=\$1MASTER_IP=\$2BACKUP_PATH="/root/backup-etcd/\${CLUSTER_NAME}"
/bin/echo [\$(date +"%F %T")] Starting \${CLUSTER_NAME} Backup... &>> /var/log/\${CLUSTER_NAME}-backup.log/bin/ssh -i /root/.ssh/ocp-acmac core@\${MASTER_IP} '/bin/sudo /usr/local/bin/cluster-backup.sh /home/core/backup && /bin/sudo /bin/find /home/core/backup -mtime +5 -delete && /bin/sudo /bin/chown -vR core:core /home/core/backup'/bin/rsync -av --delete -e "/bin/ssh -i /root/.ssh/ocp-acmac" core@\${MASTER_IP}:/home/core/backup \${BACKUP_PATH} &>> /var/log/\${CLUSTER_NAME}-backup.log/bin/echo [\$(date +"%F %T")] Terminated \${CLUSTER_NAME} Backup. &>> /var/log/\${CLUSTER_NAME}-backup.logEOFBackup ETCD cronjob:
apiVersion: v1kind: Namespacemetadata: name: ocp-backup-etcd labels: app: openshift-backup annotations: openshift.io/node-selector: ''---kind: ServiceAccountapiVersion: v1metadata: name: openshift-backup namespace: ocp-backup-etcd labels: app: openshift-backup---apiVersion: rbac.authorization.k8s.io/v1kind: ClusterRolemetadata: name: cluster-etcd-backup labels: app: openshift-backuprules:- apiGroups: [""] resources: - "nodes" verbs: ["get", "list"]- apiGroups: [""] resources: - "pods" - "pods/log" verbs: ["get", "list", "create", "delete", "watch"]---kind: ClusterRoleBindingapiVersion: rbac.authorization.k8s.io/v1metadata: name: openshift-backup labels: app: openshift-backupsubjects: - kind: ServiceAccount name: openshift-backup namespace: ocp-backup-etcdroleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: cluster-etcd-backup---apiVersion: rbac.authorization.k8s.io/v1kind: RoleBindingmetadata: name: openshift-backup-privileged namespace: ocp-backup-etcdroleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: system:openshift:scc:privilegedsubjects:- kind: ServiceAccount name: openshift-backup namespace: ocp-backup-etcd---kind: CronJobapiVersion: batch/v1metadata: name: openshift-backup namespace: ocp-backup-etcd labels: app: openshift-backupspec: schedule: "56 23 * * *" concurrencyPolicy: Forbid successfulJobsHistoryLimit: 5 failedJobsHistoryLimit: 5 jobTemplate: metadata: labels: app: openshift-backup spec: backoffLimit: 0 template: metadata: labels: app: openshift-backup spec: containers: - name: backup image: "registry.redhat.io/openshift4/ose-cli:v4.10" command: - "/bin/bash" - "-c" - oc get no -l node-role.kubernetes.io/master --no-headers -o name | xargs -I {} -- oc debug {} -- bash -c 'chroot /host sudo -E /usr/local/bin/cluster-backup.sh /home/core/backup/ && chroot /host sudo -E find /home/core/backup/ -type f -ctime +"2" -delete' restartPolicy: "Never" terminationGracePeriodSeconds: 30 activeDeadlineSeconds: 600 dnsPolicy: "ClusterFirst" serviceAccountName: "openshift-backup" serviceAccount: "openshift-backup"API Server (correlazione con error budget):
oc -n openshift-kube-apiserver get podsoc -n openshift-kube-apiserver logs <pod-apiserver> --tail=500 | egrep -i 'slow|etcd|timeout'Security
Create a secret from the CLI
oc create secret generic oia-secret --from-literal=username=myuser \--from-literal=password=mypasswordUse secret in deployment env
oc set env deployment/ --from secret/oia-secretMount the Secret on a Volume
oc set volumes dc/myapp --add --name=secret-volume --mount-path=/opt/app-root/ \--secret-name=oia-secretList Istio Authorization Policies details (extract to csv)
(echo "Namespace,Name,Action,Principals,Namespaces,Paths"; oc get authorizationpolicies.security.istio.io --all-namespaces -o json | jq -r '.items[] | [.metadata.namespace, .metadata.name, .spec.action // "N/A", (.spec.rules[]?.from[]?.source.principals[]? // "N/A"), (if (.spec.rules[]?.from[]?.source.namespaces | type) == "array" then (.spec.rules[]?.from[]?.source.namespaces | join(",")) else .spec.rules[]?.from[]?.source.namespaces end // "N/A"), (if (.spec.rules[]?.to[]?.operation.paths | type) == "array" then (.spec.rules[]?.to[]?.operation.paths | join(",")) else .spec.rules[]?.to[]?.operation.paths end // "N/A")] | @csv') > authorizationpolicies.csvCertificates
Sign all pending Certificate Signing Requests (CSRs)
oc get csr -o name | xargs oc adm certificate approveAuthenticate users using TLS certificates
- Generate a private key and CSR:
Terminal window mkdir ${OCP_USERNAME}openssl req -new -nodes -subj "/CN=${OCP_USERNAME}" \-keyout ${OCP_USERNAME}/private.key -out ${OCP_USERNAME}/request.csr - Create a CertificateSigningRequest:
Terminal window cat <<EOF | oc apply -f -apiVersion: certificates.k8s.io/v1beta1kind: CertificateSigningRequestmetadata:name: tls-auth-${OCP_USERNAME}spec:signerName: "kubernetes.io/kube-apiserver-client"request: $(cat ${OCP_USERNAME}/request.csr | base64 | tr -d '\n')usages:- digital signature- key encipherment- client authEOF - Approve the CSR:
Terminal window oc adm certificate approve tls-auth-${OCP_USERNAME}
API
API Resources
List all API resources:
oc api-resourcesAPI resources per API group
oc api-resources --api-group config.openshift.io -o nameoc api-resources --api-group machineconfiguration.openshift.io -o nameExplain resources
Explain resource details:
oc explain pods.spec.containersFor a specific API group:
oc explain --api-version=config.openshift.io/v1 schedulerMiscellaneous Commands
Manage node state
oc adm manage node <node> --schedulable=falseGet VSphere config
oc get cm cloud-provider-config -o json -n openshift-config | jq -r .data.configList installed operators
oc get csvExport resources as a template
oc export is,bc,dc,svc --as-template=app.yamlShow user in prompt
function ps1(){ export PS1='[\u@\h($(oc whoami -c 2>/dev/null|cut -d/ -f3,1)) \W]\$ '}Backup OpenShift objects
oc get all --all-namespaces --no-headers=true | awk '{print $1","$2}' | while read obj; do NS=$(echo $obj | cut -d, -f1) OBJ=$(echo $obj | cut -d, -f2) FILE=$(echo $obj | sed 's/\//-/g;s/,/-/g') echo $NS $OBJ $FILE oc export -n $NS $OBJ -o yaml > $FILE.ymldoneShow machine-config-controller logs
oc logs -n openshift-machine-config-operator $(oc get pod -n openshift-machine-config-operator -o name | grep controller)Operator stuck in “Unknown Failure” while upgrading in RHOCP 4
oc delete pods -l 'app in (catalog-operator, olm-operator)' -n openshift-operator-lifecycle-manager
oc rollout restart deployment.apps/catalog-operator deployment.apps/olm-operator -n openshift-operator-lifecycle-manager
for sub in $(oc get subs -n openshift-storage -o json | jq '.items[] | select((.metadata.annotations."olm.generated-by" | .!= null) and (.status.installplan==null)) | .metadata.name' -r); do oc patch subs -n openshift-storage $sub --type json -p '[{"op":"remove", "path":"/metadata/annotations/olm.generated-by"}]'; done;
oc delete pod -l olm.catalogSource=redhat-operators -n openshift-marketplaceoc delete pod -l app=catalog-operator -n openshift-operator-lifecycle-manageroc patch sub ${SUBSCRIPTION} -n ${PROJECT} --subresource=status --type json -p '[{"op":"remove","path":"/status/conditions"}]'Operator Upgrade Not Progressing [https://access.redhat.com/solutions/7020921]
for OPERATOR in ocs-operator mcg-operator odf-operator odf-csi-addons-operator cephcsi-operator ocs-client-operator odf-prometheus-operator rook-ceph-operator recipe odf-dependencies; do export OPERATOR; oc get job -n openshift-marketplace -o json | jq -r '.items[] | select(.spec.template.spec.containers[].env[].value|contains (env.OPERATOR)) | .metadata.name' >> /tmp/jobs; done
cat /tmp/jobs ( example, could be many more in customer env.)6d97dfcfa4d148a766632d834e1ebbd6fa245631f49e8243eb42ff5967229696f70c8b65e5a693e11613dd966e9a37bb81e3324323c2dfe14badc99e71077e
for i in `cat /tmp/jobs`; do oc delete job $i -n openshift-marketplace; oc delete configmap $i -n openshift-marketplace; done
oc delete installplans -n openshift-storage --alloc delete subs odf-operator -n openshift-storageoc get subs -n openshift-storagefor i in $(oc get csv -n openshift-storage -o name | grep rhodf); do oc delete $i -n openshift-storage; doneoc get catalogsource -n openshift-marketplace|grep redhat-operatorsoc delete pods -l 'app in (catalog-operator, olm-operator)' -n openshift-operator-lifecycle-manager
$ vi subscription.yaml
apiVersion: operators.coreos.com/v1alpha1kind: Subscriptionmetadata: name: odf-operator namespace: openshift-storagespec: channel: "stable-4.14" # <-- Channel should be modified depending on the OCS version to be installed. Please ensure to maintain compatibility with OCP version installPlanApproval: Automatic name: odf-operator source: redhat-operators # <-- Modify the name of the redhat-operators catalogsource if not default sourceNamespace: openshift-marketplace
$ oc apply -f subscription.yamlRetrieve MachineNetwork, Pod CIDR, Service CIDR
echo -n "Pod CIDR (clusterNetwork): " ; oc get network.config.openshift.io cluster -o jsonpath='{.spec.clusterNetwork[*].cidr}{"\n"}'echo -n "Service CIDR (serviceNetwork): " ; oc get network.config.openshift.io cluster -o jsonpath='{.spec.serviceNetwork[*]}{"\n"}'echo -n "Machine Network: " ; oc get infrastructure.config.openshift.io cluster -o jsonpath='{.status.platformStatus.vsphere.machineNetworks}{"\n"}'
- GCP
gcloud compute instances list \ --project gcp-prj-ocp-srv-prd-001 \ --filter="name~'^ocp-prd-f5ckt-'" \ --format="table(name,zone,networkInterfaces[0].network,networkInterfaces[0].subnetwork,networkInterfaces[0].networkIP)"ODF
Script to patch CephTools
oc exec -n openshift-storage deployment/rook-ceph-tools -- ceph status
ceph statusceph osd statusceph osd pool lsceph dfrados df
ceph health detailceph versionsceph config dumpceph osd df treeceph osd pool ls detailceph dfceph osd dumpceph pg dumpceph reportceph osd pool autoscale-statusceph osd crush dump
#!/bin/bashif [ "$1" == "off" ]; then oc patch OCSInitialization/ocsinit -n openshift-storage \ --type=merge -p='{"spec":{ "enableCephTools": false}}' sleep 3 echo "removing any existing toolbox pod" oc delete pods -n openshift-storage -l app=rook-ceph-toolselse oc patch OCSInitialization/ocsinit -n openshift-storage \ --type=merge -p='{"spec":{ "enableCephTools": true}}'
TOOLS_POD="" echo -n "waiting for ceph tools pod to schedule " until [ -n "$TOOLS_POD" ]; do echo -n "." sleep 5 TOOLS_POD=$(oc get pod -n openshift-storage -l app=rook-ceph-tools -o name) done echo "$TOOLS_POD"
echo "waiting for ceph tools pod to startup" oc wait $TOOLS_POD --for=condition=Ready --timeout=300s -n openshift-storage
echo "connecting to ceph toolbox" oc rsh -n openshift-storage $TOOLS_PODfiCeph Status
oc exec -it $(oc get pod -n openshift-storage -l app=rook-ceph-operator -o name) -n openshift-storage -- ceph status -c /var/lib/rook/openshift-storage/openshift-storage.configCeph Time Sync
oc exec -it $(oc get pod -n openshift-storage -l app=rook-ceph-operator -o name) -n openshift-storage -- ceph time-sync-status -c /var/lib/rook/openshift-storage/openshift-storage.configStorageCluster Status
oc get storagecluster -n openshift-storageNoobaa check oggetti e size
radosgw-admin bucket stats | jq -r '.[] | "\(.bucket) objs=\(.usage["rgw.main"].num_objects) sizeGB=\(.usage["rgw.main"].size_kb/1024/1024|floor)"'Check bucket status.
oc get ob -o custom-columns=NAME":metadata.name",BUKCKET_NAME":spec.endpoint.bucketName",STORAGE-CLASS":spec.storageClassName",PHASE":status.phase"
https://access.redhat.com/documentation/en-us/red_hat_openshift_data_foundation/4.12/html-single/managing_hybrid_and_multicloud_resources/index#accessing-the-Multicloud-object-gateway-from-the-mcg-command-line-interface_rhodf
noobaa bucket status {bucket_name}